I recently took a small detour to learing about graph databases.
Here are some notes about my findings:
A friend of a friend (Donald), runs a business that sells school books to
various schools (both public and charter).
Just like any other business, he feels that he can improve his bottom line and
reaches out to me, a “Consultant” :) for help
Here are his primary set of questions:
- How much inventory should I keep?
- How can I track my sales in all states where I have stores?
- How can I analyze what books are sold in what markets?
- When should I use promotions?
- How can I negotiate my RMAs (Return to Manufacturer Agreements)?
We engage and here is what emerges:
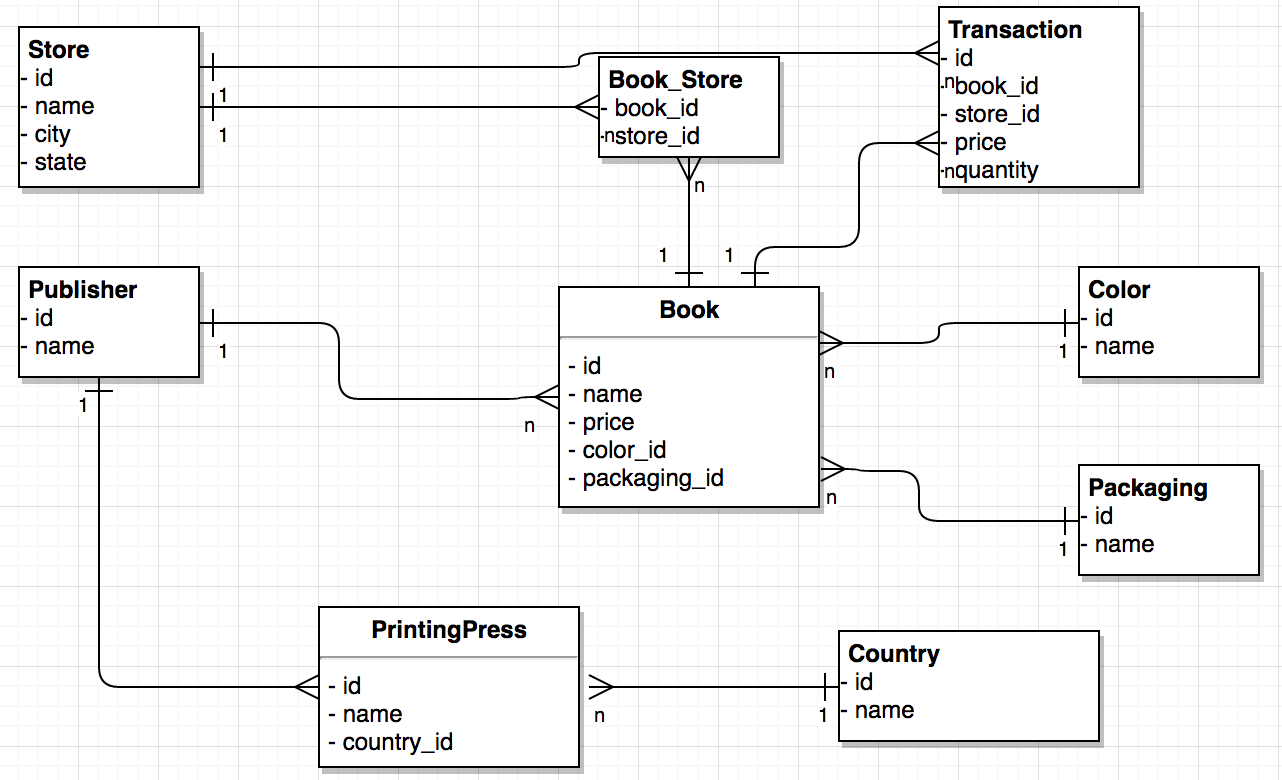
- BOOKs are published by PUBLISHERs
- PUBLISHERs have PRINTING_PRESSes
- PRINTING_PRESSes exist in COUNTRYs
- BOOKs have a PACKAGING
- BOOKs have a COLOR
- Some BOOKS have a SHIPPING_POLICY
- All BOOKs sold are recorded as a TRANSACTION where attributes of the sale are recorded.
At this time I’m tempted to place this information in a fully normalized RDBMS
like MySQL or Oracle.
What would that entail? Perhaps this ERD will be a good indication:
Challenges
However, here are some challenges that we have to solve:
- Not all BOOKs have the same attributes. This will cause the BOOK table to be
sparsely populated.
- Since BOOKs arrive at different STOREs from several PRINTING_PRESSes
around the country, the Id’s of these books do not always sync up.
So, Harry Potter - The Deathly Hallows sold in Seattle may have a different
id that the same book sold in NewYork. Therefore, in the TRANSACTION table,
we cannot rely on the fact that the same ID will refer to the same book.
This causes reports (that are used by the PUBLISHERs for analysis) built off
of the TRANSACTION table, to be messed up.
- This equivalence of Ids is different for different PUBLISHERs. For example,
some PUBLISHERs
consider a blue Harry Potter - Deathly Hallows to be the same as a red book
by the same name, but some PUBLISHERs would like them to be treated separately.
- As more reading material is published, the attributes that need to be tracked
with each BOOK, keep changing.
As we can see, the above challenges can be solved using a RDBMS based storage
solution (and have been for years). But in this post, I’d like to suggest how to use a
combination of a Graph db and an RDBMS to reduce the pain in addressing these
challenges.
A Graph based solution
Approach:
First we will identify fact tables and dimension tables: Based on our model above,
it is obvious that the TRANSACTION table is our fact table and all others
would be dimension tables.
Then we will store all dimension data in a Graph db and store the transaction
data in an RDBMS.
The rationale for this is that dimensions are what Graphs are good at manipulating and
maintaining. There is not much churn on fact tables, but their normalized nature
tends to make them good candidates for the RDBMS.
Note that dimension tables tend to be smaller than fact tables in most domains.
But that has no bearing on the above strategy.
The implementation
We will use Neo4J for our Graph db and MySQL for our RDBMS.
Please download and install
neo4j (Should take ~ 5 mins!)
Then experiment with the sample movie db (should take no more than an hour max)
Then, in your browser at localhost:7474, copy and paste this into your command window and execute it.
CREATE (physicsPendulum: Book {id: '001', name: 'Physics Pendulum', price: 15})
CREATE (mathMayhem: Book {id: '002', name: 'Math Mayhem', price: 9})
CREATE (chemistryChaos: Book {id: '003', name: 'Chemistry Chaos', price: 11})
CREATE (trigTurpitude: Book {id: '004', name: 'Trignometry Turpitude', price: 17})
CREATE (theCornerPub: Publisher {id: '005', name: 'The Corner Pub'})
CREATE (theGoodPub: Publisher {id: '006', name: 'The Good Pub'})
CREATE (peteThePublisher: Publisher {id: '007', name: 'Pete the Publisher'})
CREATE (inBlackAndWhite: PrintingPress {id: '008', name: 'In Black And White'})
CREATE (theStencil: PrintingPress {id: '009', name: 'The Stencil'})
CREATE (featherAndInk: PrintingPress {id: '010', name: 'Feather And Ink'})
CREATE (gautemala: Country {id: '011', name: 'Gautemala'})
CREATE (syria: Country {id: '012', name: 'Syria'})
CREATE (red: Color {id: '013', name: 'red'})
CREATE (blue: Color {id: '014', name: 'blue'})
CREATE (green: Color {id: '015', name: 'green'})
CREATE (hardcover: Packaging {id: '016', name: 'Hardcover'})
CREATE (paperback: Packaging {id: '017', name: 'Paperback'})
CREATE (booksNThings: Store {id: '018', name: 'Books and Things', city: 'Pittsburgh', state: 'PA'})
CREATE (bookWorm: Store {id: '019', name: 'Book Worm', city: 'Anahiem', state: 'CA'})
CREATE (nerdCorner: Store {id: '020', name: 'Nerd Corner', city: 'Armadillo', state: 'TX'})
// Relationships
CREATE
(physicsPendulum)-[:PUBLISHED_BY]->(printedPurgatory),
(physicsPendulum)-[:REFLECTS]->(red),
(physicsPendulum)-[:PACKAGED_IN]->(hardcover),
(mathMayhem)-[:PUBLISHED_BY]->(onlyGoodBooks),
(mathMayhem)-[:REFLECTS]->(blue),
(mathMayhem)-[:PACKAGED_IN]->(hardcover),
(chemistryChaos)-[:PUBLISHED_BY]->(printedPurgatory),
(chemistryChaos)-[:REFLECTS]->(green),
(chemistryChaos)-[:PACKAGED_IN]->(paperback),
(trigTurpitude)-[:PUBLISHED_BY]->(peteThePublisher),
(trigTurpitude)-[:REFLECTS]->(red),
// Note that the trig book is in both packaging
(trigTurpitude)-[:PACKAGED_IN]->(hardcover),
(trigTurpitude)-[:PACKAGED_IN]->(paperback)
CREATE
(printedPurgatory)-[:PRINTS_AT]->(inBlackAndWhite),
(onlyGoodBooks)-[:PRINTS_AT]->(theStencil),
(peteThePublisher)-[:PRINTS_AT]->(featherAndInk)
CREATE
(inBlackAndWhite)-[:LOCATED_IN]->(gautemala),
(theStencil)-[:LOCATED_IN]->(gautemala),
(featherAndInk)-[:LOCATED_IN]->(syria)
CREATE
(physicsPendulum)-[:SOLD_IN]->(booksNThings),
(booksNThings)-[:SELLS]->(physicsPendulum),
(mathMayhem)-[:SOLD_IN]->(bookWorm),
(bookWorm)-[:SELLS]->(mathMayhem),
(chemistryChaos)-[:SOLD_IN]->(booksNThings),
(booksNThings)-[:SELLS]->(chemistryChaos),
(trigTurpitude)-[:SOLD_IN]->(nerdCorner),
(nerdCorner)-[:SELLS]->(trigTurpitude)
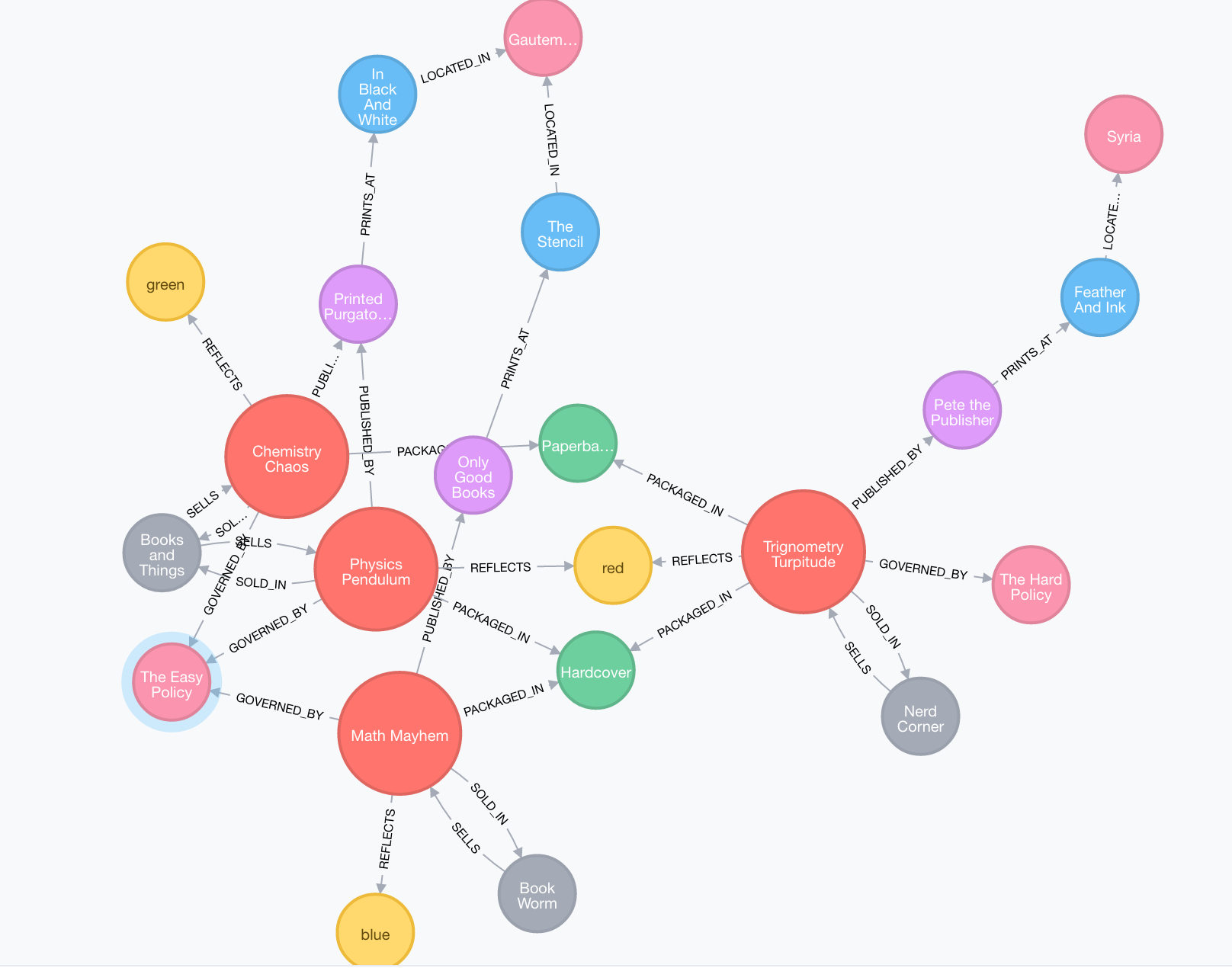
By doing above we have created the Dimension entities in the Graph Db and also used the data
to establish relationship between them.
Let’s query and see what we have got so far:
Run the following to view the schema:
call db.schema;
This yields:
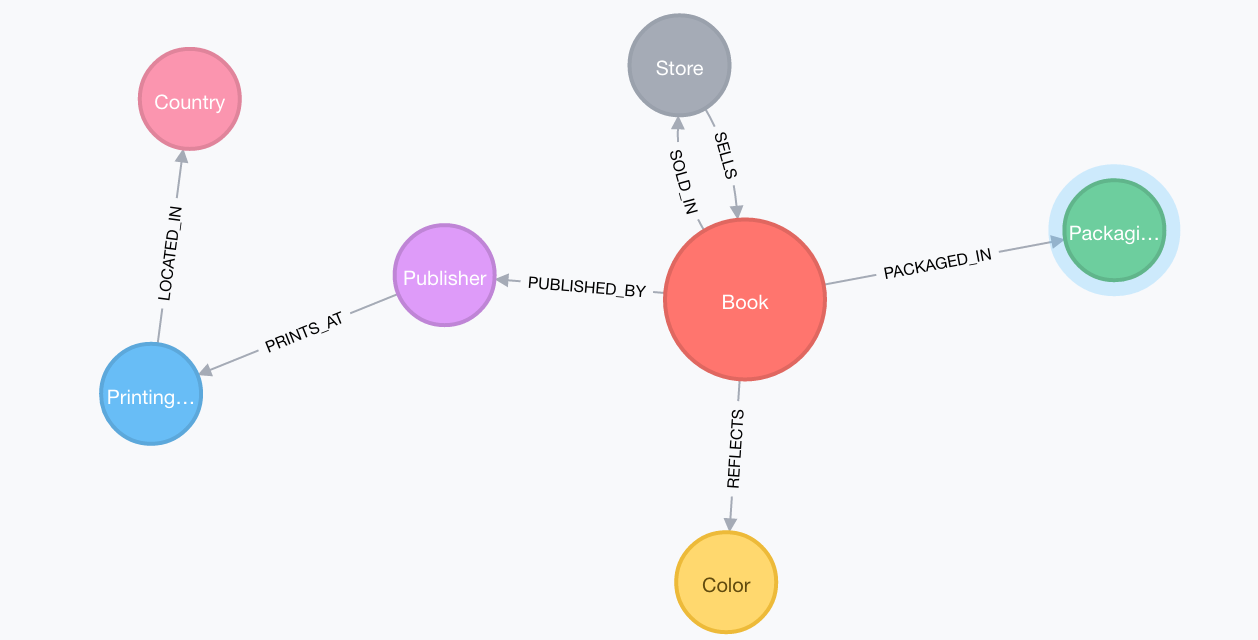
But since we don’t have much data, we can actually pull the entire dataset and view
relationships (without blowing up the browser!):
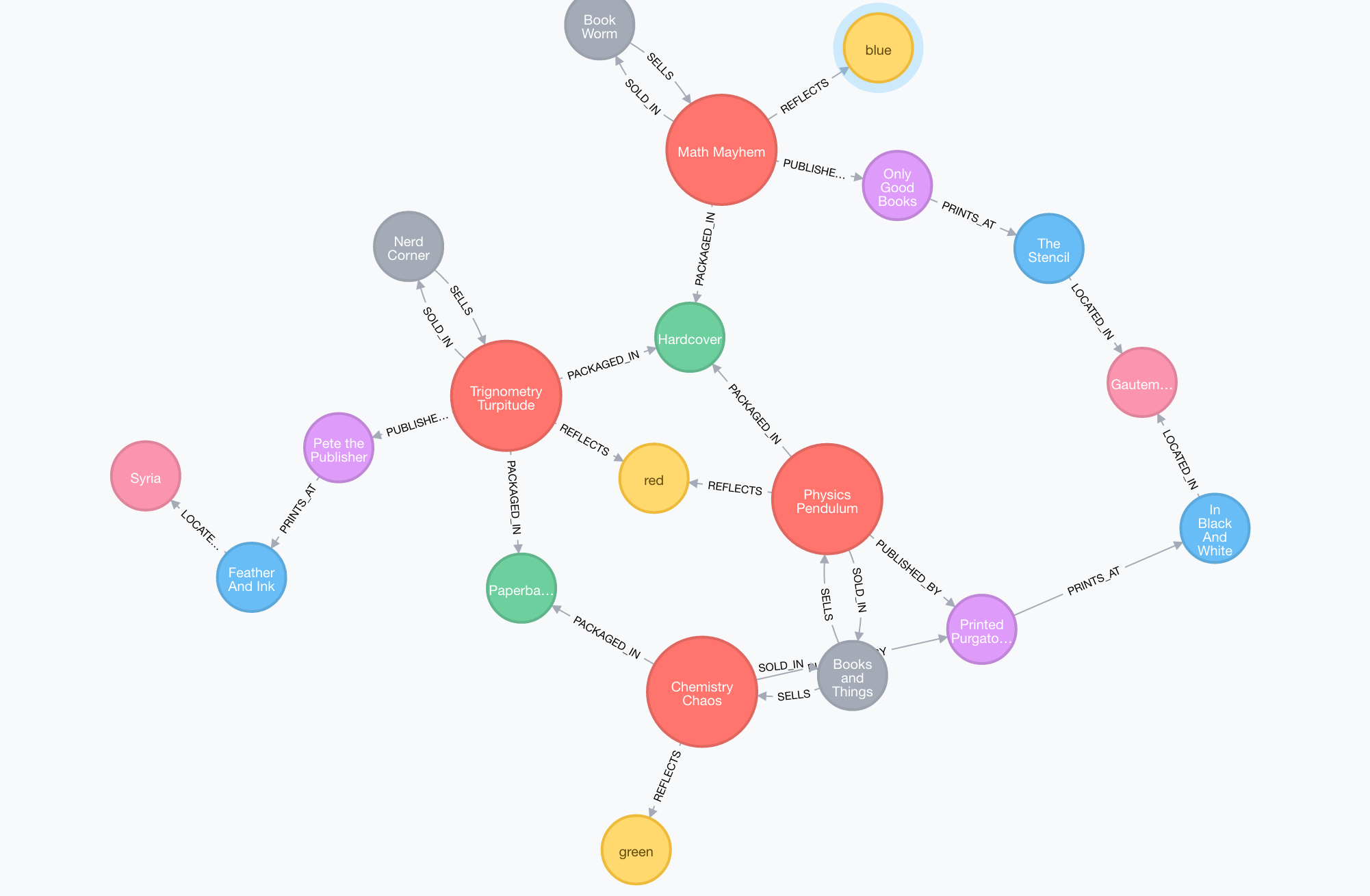
The first thing to notice is that the optional “properties” of color and
packaging is handled via a relationship instead of as an inline property of
the book (such as is the case with price).
Now let’s create the TRANSACTION table in MySQL.
Please create a database and run the appropriate DDL and INSERT statements to yield
the following data in the TRANSACTION table:
id bookId, qty, price, storeId
1 001 2 10.00 020
2 002 3 11.50 030
3 003 4 12.5 040
4 001 3 36.00 030
5 002 4 54.00 040
6 002 1 05.00 020
So now let us address the problem where the blue and red Harry Potter books are the
same for PUBLISHER1 but different for PUBLISHER2
For PUBLISHER1 book 001 and book 002 are euivalent
For PUBLISHER2 book 002 and 003 are equivalent.
This Cypher statement will establish that equivalence:
MATCH (b:Book {id: '001'})-[*]-(c: Book {id: '002'})
MERGE (b)-[e: EQUIVALENT {publisher: 'PUBLISHER1', equivalentId: '1001'}]->(c)
MATCH (b:Book {id: '002'})-[*]-(c: Book {id: '003'})
MERGE (b)-[e: EQUIVALENT {publisher: 'PUBLISHER2', equivalentId: '1002'}]->(c)
Notice how we have:
- Created publisher-specific relationships
- Identified the equivalent id for each pair in the relationship properties and
associated it to the relationship.
This yields the following schema:
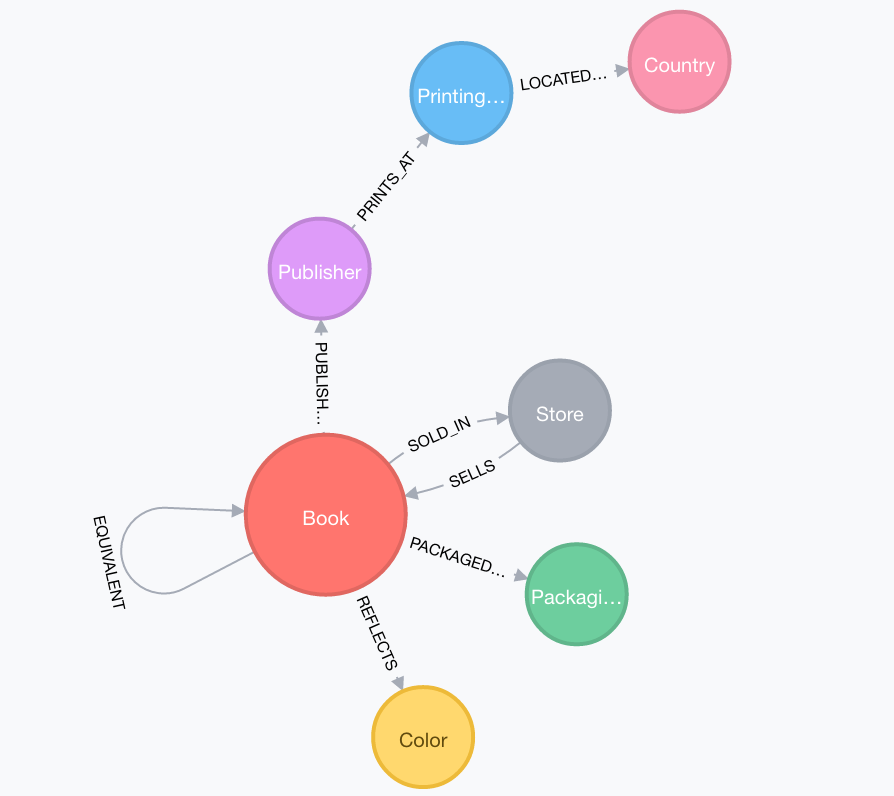
And the same relationship is displayed with the data:
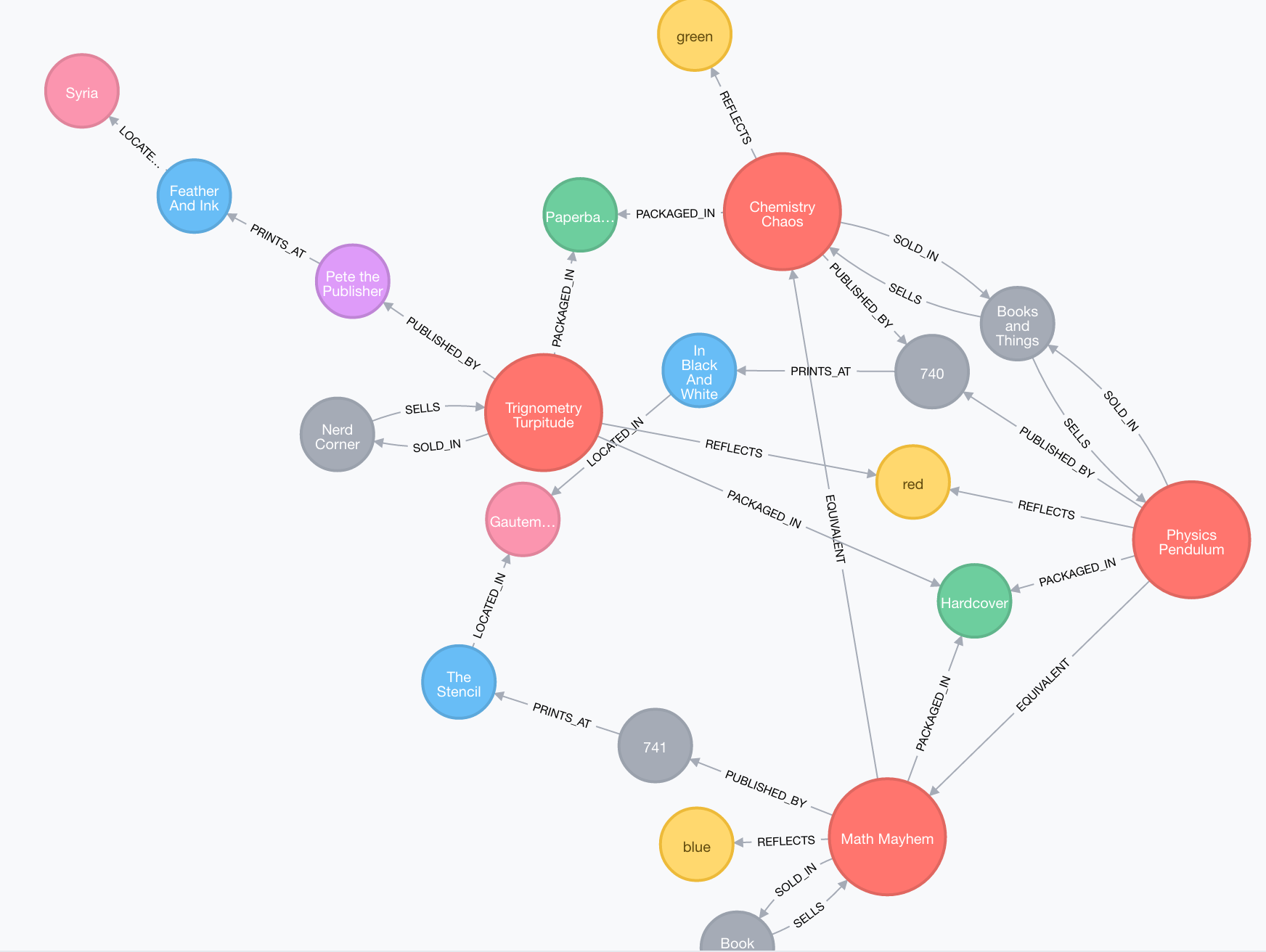
Querying
Now let’s see how we can write queries for the two publishers using this equivalence
relationship and the transaction data stored in a relational db.
First pull dimension data using Neo4J for PUBLISHER1.
MATCH (b1: Book)-[r1]-(b2: Book), (b: Book)-[*]-(p)-[*]-(r)-[*]-(c: Country)
WHERE r1.publisher = 'PUBLISHER2'
RETURN DISTINCT b1, b2, r1.equivalentId, b, p, r, c;
Fact data that is stored in MySQL can be accessed in either of two ways:
- Use the JDBC plugin for Neo4J to make a direct connection .
- Use the Neo4J API to programatically access data.
Here’s an example of how this model can be queried using plain Cypher querries:
Give me all books that are red in color, printed in Gautemala, sold in PA and cost
more than $10.00
MATCH (b:Book)-[:PUBLISHED_BY]->()-[:PRINTS_AT]->()-[:LOCATED_IN]->(c:Country),
(b:Book)-[:REFLECTS]-(r:Color),
(b:Book)-[:SOLD_IN]->(s:Store)
WHERE c.name = 'Gautemala'
AND b.price > 10
AND r.name = 'red'
AND s.state = 'PA'
RETURN b;
CREATE (easyPeasy:ShippingPolicy {id: '021', name: 'The Easy Policy'})
CREATE (hardAsNails:ShippingPolicy {id: '022', name: 'The Hard Policy'})
MATCH (b:Book)-[:PUBLISHED_BY]->()-[:PRINTS_AT]->()-[:LOCATED_IN]->(c:Country)
WHERE c.name = 'Gautemala'
CREATE
(b)-[:GOVERNED_BY]->(s:ShippingPolicy)
But now delete relationship at schema level
MATCH (a)-[r:GOVERNED_BY]->(b)
DELETE r;
And create the same at data level (for specific data that meets a condition):
MATCH (b:Book)-[:PUBLISHED_BY]->()-[:PRINTS_AT]->()-[:LOCATED_IN]->(c:Country)
MATCH (p:ShippingPolicy)
WHERE c.name = 'Gautemala'
AND p.name = 'The Easy Policy'
CREATE
(b)-[:GOVERNED_BY]->(p)
MATCH (b:Book)-[:PUBLISHED_BY]->()-[:PRINTS_AT]->()-[:LOCATED_IN]->(c:Country)
MATCH (p:ShippingPolicy)
WHERE c.name = 'Syria'
AND p.name = 'The Hard Policy'
CREATE
(b)-[:GOVERNED_BY]->(p)